library(tidytext)
library(widyr)
library(ggraph)
library(igraph)
df_preco <- qs::qread("data/retraites_sub") |>
distinct(value_autre, value_autre_cat) |>
rowid_to_column()
df_preco_words <- df_preco |>
unnest_tokens(input = value_autre, "word") |>
filter(!word %in% proustr::stop_words$word)
df_preco_words |>
count(word, sort = TRUE)Analyser du texte en SHS avec une IA locale - un aperçu
Rencontres R 2025
Thomas VRoylandt, Kantiles
VictoiRe Chatain, Kantiles
Emmanuel HeRbepin, Kantiles
https://github.com/kantiles/rr_2025_ia

Une diversité des formes de textes
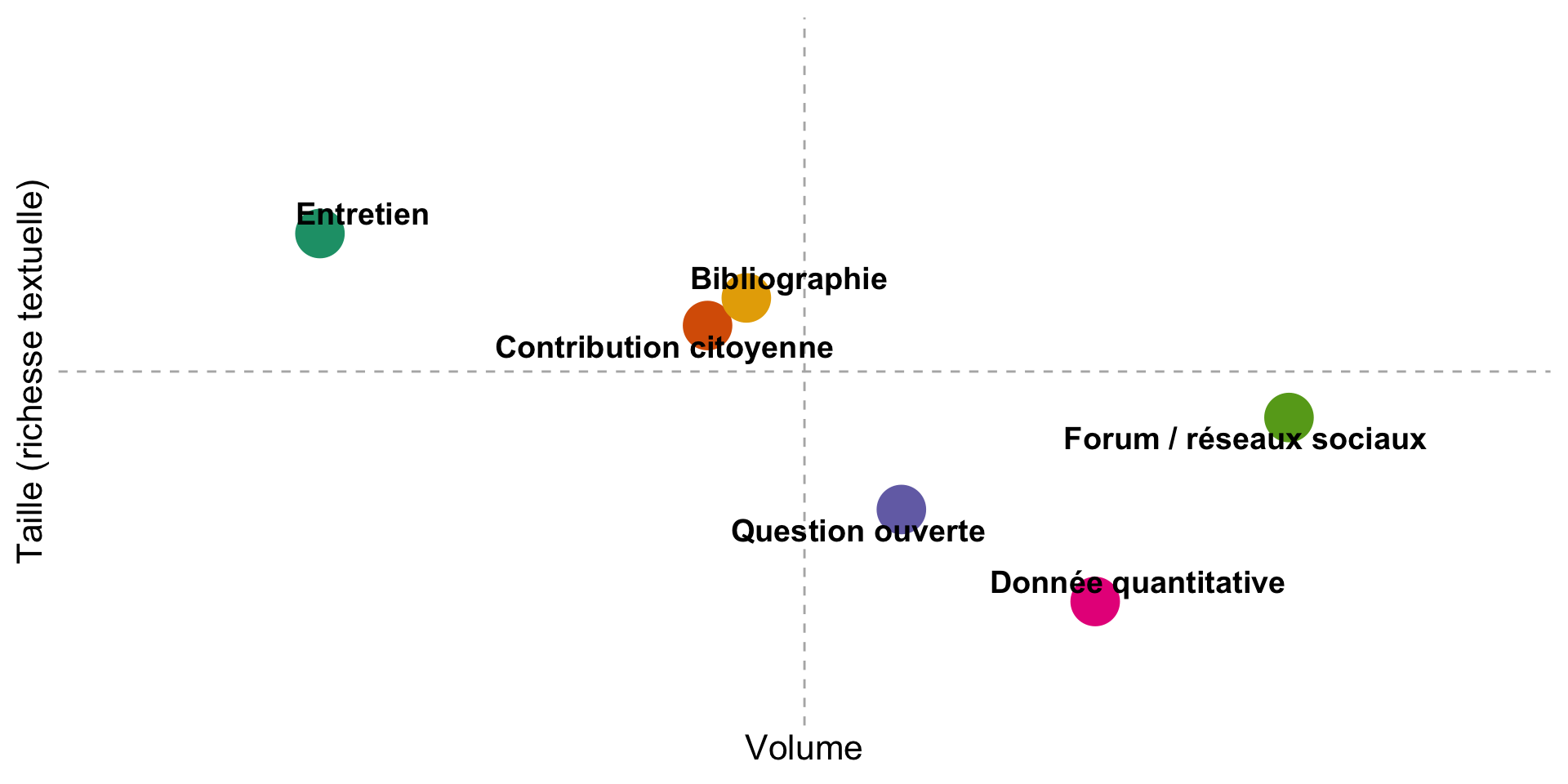
Des modalités de recueil différentes
- Sondage quantitatif
- Contributions citoyennes
- Entretiens qualitatifs
- Synthèses bibliographiques
- Scraping/API
Un objectif commun : rendre l’information exploitable
- Catégoriser/classer
- Résumer
- Distinguer des entités
- Comparer
Solutions possibles
- Synthèse “experte” = papier/crayon
- Analyse textuelle : compter les mots, les n-grammes, utiliser des dictionnaires
- Version historique : Lebart & Salem
- Version actuelle :
tidytext
- Classer avec des algorithmes : Bert, FastText
- Utiliser un modèle de langage : LLM
Les enjeux des LLM
- Coût
- Performance
- Confidentialité
- Impact écologique
L’IA et R
Ollama

==> Permet de faire tourner certains modèles en local
Performance forcément moindre
Mais pas de sorties de données
Coût quasi nul et impact écologique plus réduit
Accepte les input/outputs structurés
Dans R
{ollamar}: https://hauselin.github.io/ollama-r/- Interface avec Ollama
- Permet de gérer les modèles
Dans R
{mall}: https://mlverse.github.io/mall/- Wrapper plus haut niveau
- Compatible avec le
tidyverse - Cache
- Fonctions d’analyses par défaut : prompts pré-remplis ==>
llm_classify:"You are a helpful classification engine. {labels}. No capitalization. No explanations. {additional} The answer is based on the following text:\n{{text}}"
Dans R
{ellmer}: https://ellmer.tidyverse.org/- Plus large que l’IA local
- Package généraliste pour l’accès aux LLM
- Options de paramétrage beaucoup plus poussées
Consultation citoyenne sur les retraites
Contexte : avant la réforme des retraites 2019
Question : Afin de compenser les périodes de chômage, le futur système universel de retraites doit-il :
- Attribuer autant de points que si la personne travaillait
- Attribuer des points à hauteur de l’allocation chômage
- Ne pas attribuer de points pour les périodes de chômage
- Autres
Que faire des 2400 réponses “autres” ?
Classiquement : compter les mots
Classiquement : compter les mots
Classiquement : regarder les corrélations entre mots
Classiquement : regarder les corrélations entre mots

Classiquement
Autres options :
- Corrélation :
- TF-IDF
- Latent Dirichlet Allocation (LDA)
- Apprentissage supervisé :
- BERT et ses déclinaisons (CamemBERT pour le français par exemple)
- FastText
Focus sur llm_use()
Précise les paramètres :
Pour utiliser un nouveau modèle : ollamar::pull("mistral:7b")
mall::llm_classify()
df_preco_classify <- llm_classify(
head(df_preco, 200),
value_autre,
labels = c(
'Propose un système alternatif' ~ 1,
'Ajout d un maximum' ~ 2,
'Réduction du nombre de point' ~ 3,
'Condition' ~ 4,
'Veut garder le système précédent' ~ 5,
'Autre idée non liée à la question ou sans opinion' ~ 6
),
pred_name = "categ",
additional_prompt = "Classe ces réponses à la question 'Afin de compenser les périodes de chômage, le futur système universel de retraites doit-il ?'"
)Avec Mistral 7b –> 25% de classés comme notre annotation manuelle
## Notre prompt
- Prend environ 45s pour 200 lignes (80 caractères en moyenne)
- Renvoie NA pour les lignes qu’il ne parvient pas à classer
- Que valent nos résultats ? –> cela dépend beaucoup du modèle choisi
Sans catégories : mall::llm_summarise()
On peut vouloir ne pas préciser les catégories en amont
–> 168 catégories pour 200 lignes !
Sans catégories : mall::llm_summarise()
- Maintain
- Attribution
- Compensate unemployment periods, yes.
- Evaluate justified periods of unemployment. Distinguish between temporary jobs, economic layoffs and unemployed, disguised vacations.
- Tax robots
- Compensate duration of unemployment
- Assimilation, Facturation
- Compensate
- Compensate, Contribution, Periods, Allocation, Points
- Maximum Years
- Solidarité nationale + Minimum + Individuellement cotisé
- Depends (on whether unemployment is short or long)
- Emploi, Parité, Inspecteurs
- Contribuer
- Compensate unemployment periods
- Compensate, Points, Forfait, Annees, Cotisees
- Injustice
- Attribuer points
- Verifier fréquence, durée et raison des périodes de chômage.
- Compensate
Sans catégories : mall::llm_summarise()
- Même durée
- Ne respecte pas forcément strictement le
max_words - Grande diversité des réponses
Catégoriser - avec mall::llm_custom()
df_preco_categ_custom <- llm_custom(
df_preco |>
head(200) |>
summarise(
value_autre = paste(value_autre, collapse = "\n"),
.groups = "drop"
),
value_autre,
prompt = "Voici les réponses 'autres' à la question 'Afin de compenser les périodes de chômage, le futur système universel de retraites doit-il ?'. Donne moi les 3 idées principales qui ressortent"
)
df_preco_categ_custom$.predCatégoriser - avec mall::llm_custom()
Voici quelques idées sur l’attribution de points en cas de chômage :. Attribuer la moitié des points par rapport à la situation ou la personne travaillait.. Laisser la possibilité de cotiser et attribuer le nombre de points en conséquence.. Attribuer autant de points que si la personne travaillait, mais seulement pour une période donnée (ex : 1 an).. Attribuer des points en fonction du motif de la période de chômage et des efforts réalisés pour retrouver un emploi.. Attribuer des points à hauteur de l’allocation avec un minimum y compris si fin de période d’allocation.. Garder le calcul de la retraite sur les 25 meilleures années (voire les 15 meilleures).. Attribuer moins de points en cas de chômage volontaire ou non recherche d’emploi.. Traiter en amont : création d’emploi, arrêter les suppressions de postes.. Attribuer des points hors sujet (ex : formation professionnelle).. Financement de points par la couverture chômage.. Forfait points.. Conserver le système actuel.. Cotiser sur l’allocation de chômage.. Attribuer autant de points pendant un certain temps avant de diminuer.. Attribuer des points à hauteur des allocations mais avec une limite (pas plus de x points/annees cumulées).”
Options possibles
- Ajouter du contexte au prompt, voir le customiser entièrement :
llm_custom() - Expliciter encore les catégories et leur contenu :
- Configurer les paramètres :
llm_use() - Tester différents modèles :
llama3.1,mistal:7b, … - Optimiser les options de Ollama : GPU notamment
- Vérifier une assertion avec
llm_verify()
La solitude des jeunes adultes
Entretiens
- Objectif de l’étude : explorer les causes et vécus de la solitude chez les 18-24 ans en situation de précarité
- Data :
- 48 participants
- 4 boroughs défavorisés
Quelles sont les émotions exprimées dans les entretiens ?
Analyse classique : tidytext
- On nettoie le texte
Analyse classique : tidytext
On utilise des dictionnaires, Bing ou AFINN par exemple

- On peut calculer des “scores” sur chaque entretien
Analyse avec mall::llm_sentiment()
- Recourir à un LLM permet d’utiliser davantage le contexte de chaque réponse
# # A tibble: 200 × 4
# id question answer .sentiment
# <dbl> <chr> <chr> <chr>
# 1 1 Can we start by talking about what you’… yea, … negative
# 2 1 And, how does that make you feel? Uuum,… negative
# 3 1 Can you tell me more about that? Um, u… negative
# 4 1 So people not being able to understand … [Inte… negative
# 5 1 Thank you. Is there anything else you w… Just … negative
# 6 1 Yes. Yeah,… negative
# 7 1 When you say ‘shared experience’ can yo… So, j… negative
# 8 1 Thank you. Is there anything else you w… No, t… negative
# 9 1 Thank you. Numbe… neutral
# 10 1 Sure. Um, t… negative Analyse avec mall::llm_sentiment()
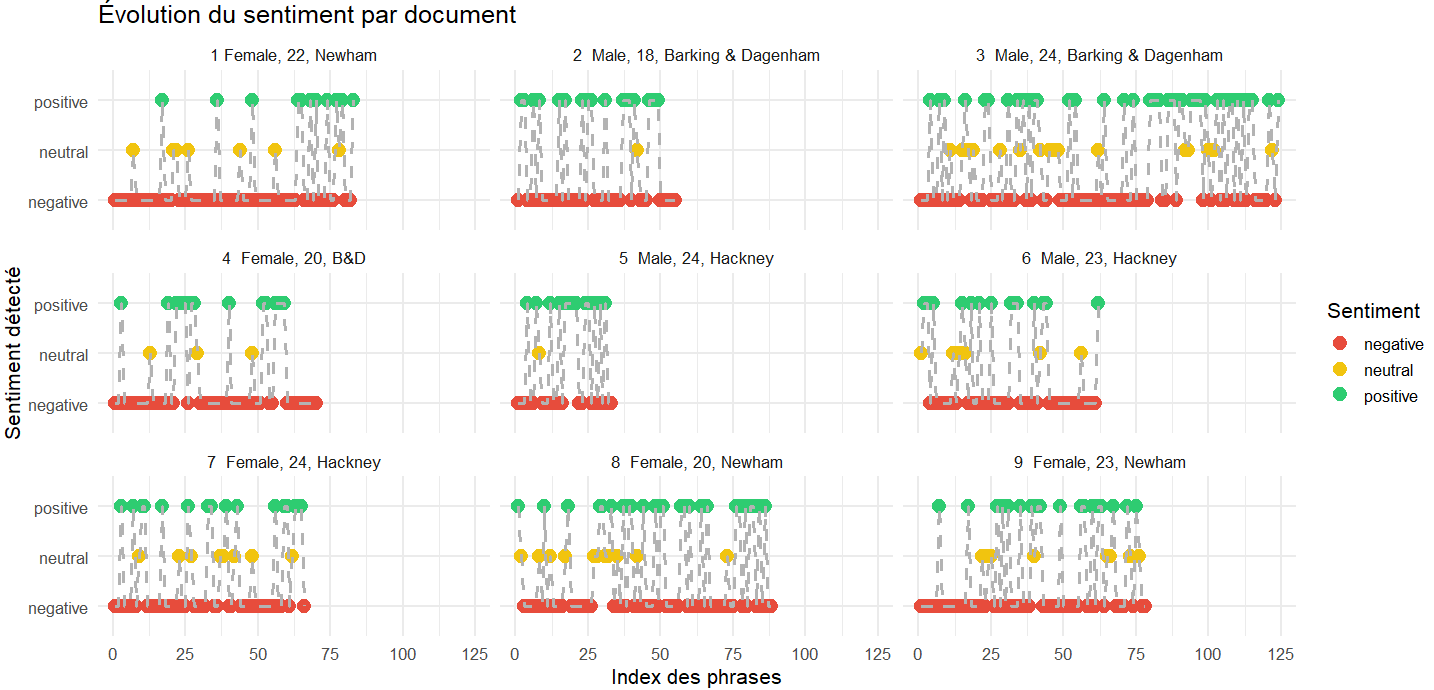
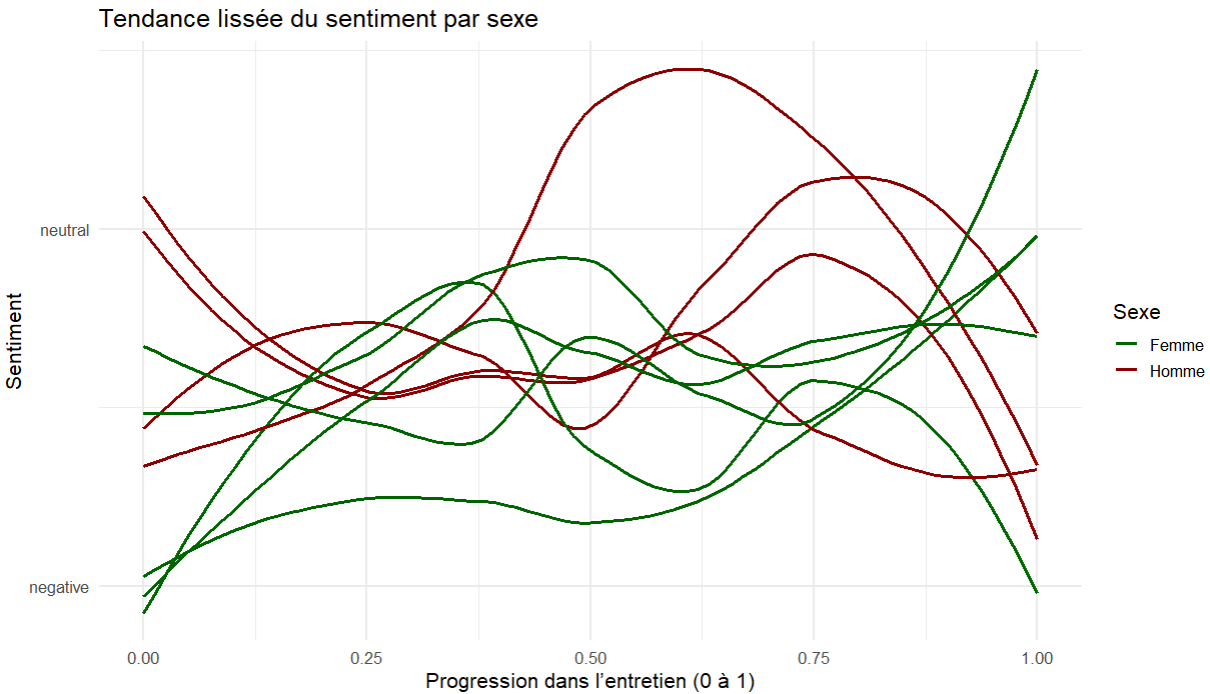
Des tendance à lier avec les questions des entretiens ?
Analyse avec mall::llm_sentiment() - Likert
On peut raffiner en demander une échelle de Likert plutôt qu’une classification en 3
my_prompt = paste(
"Réponds à la question suivante.",
"Ne retourne que la réponse, sans explication.",
"Les réponses acceptées sont sur une échelle de 1 à 7,
7 est très heureux, et 1 est très triste.",
"À partir de ce texte : la personne semble-t-elle heureuse ?"
)
choice_likert <- df_entretien |>
llm_custom(answer, prompt = my_prompt)
choice_likert |>
count(.pred)Puis en %
Des différences ?
Résultats
Traductions
Original (anglais)
“So this was like the difference between the amount of friends that you may have online versus the amount of friends that you have in person. So it’s really easy to just sort of log on and feel like you’ve got a really good sense of connection with the people that—let’s say live in London, but then when you close the computer, it’s like, oh well, it’s just me again now. [Laughs]”
Traduction humaine
“Donc c’était la différence entre le nombre d’amis en ligne et ceux en personne. C’est facile de se connecter, mais une fois l’ordi fermé, on se retrouve seul… C’est vraiment facile de se connecter et d’avoir l’impression d’un vrai lien avec les gens qui — disons — vivent à Londres. Mais quand tu éteins l’ordinateur, c’est genre : ah, je suis seul à nouveau.”
Style oral conservé, nécessite une intervention humaine
LLM standard (mall)
“Ce que j’ai ressenti, c’est la différence entre les amis en ligne et ceux en personne. C’est facile de s’identifier avec des gens à Londres, mais une fois l’ordinateur fermé, c’est comme si je restais seul.”
Contenu très lissé, et raccourci. Résumé
LLM custom (prompt)
“C’est vraiment la différence entre le nombre d’amis que tu peux avoir en ligne et ceux que tu as en face de toi. C’est facile de se connecter avec les gens qui vivent à Londres, par exemple, mais quand tu fermes l’ordi, c’est comme… ben, c’est juste moi à nouveau [rires].”
Style oral bien restitué, mais lent
Résultats
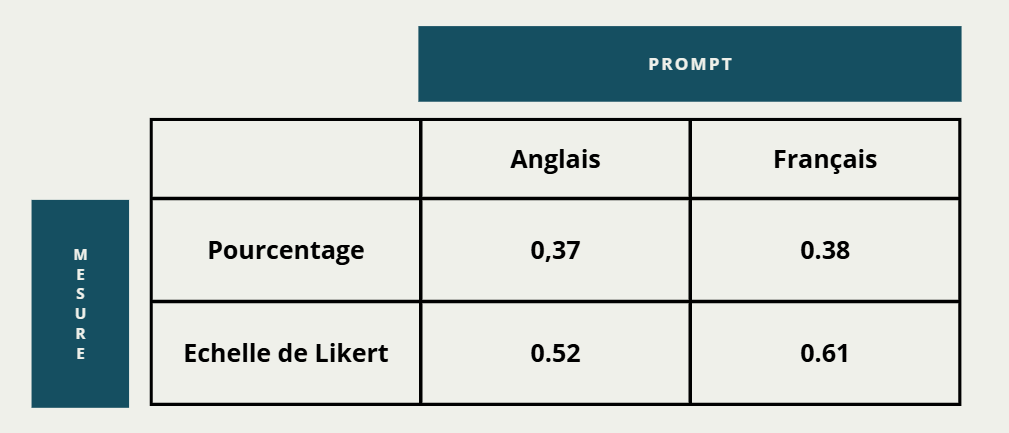
| ID | Langue | Echelle 1–5 | Echelle % |
|---|---|---|---|
| Original | en | 3 | 45 |
| Trad humaine | fr | 2 | 23 |
| LLM_trad | fr | 2 | 55 |
| LLM_custom | fr | 2 | 60 |
- Le modèle ne calcule rien
- Il joue sur les résultats
Perspective d’usage dans d’autres disciplines : Histoire

Archives de la police (BNF, MS 11661)
- Extraire les auteurs des documents (
llm_extract)
- Résumer les actes de demande de mise en liberté (
llm_sumarize)
De nombreuses opportunités…
Avec ellmer - résumer un entretien
library(ellmer)
chat <- chat_ollama(
model = "mistral:7b",
system_prompt = "This is an interview about lonelisness in England. You will be provided questions and answers from youth people, please summarise it in 50 words"
)
df_chat_result <- chat$chat(
df_entretien |>
filter(id == 1) |>
summarise(text = paste(paste(question, "--", answer), collapse = "\n")) |>
pull(text)
)It sounds like this individual has two very distinct experiences in his community: one where he feels connected and part of the social fabric (the barbershop), and another where he feels detached and disconnected (the shopping center after 7pm). The connection at the barbershop, with sports and camaraderie, provides a sense of belonging and happiness. In contrast, encountering homeless individuals in the shopping center fills him with feelings of loneliness, resentment, and disconnection from his community, as he feels alienated by the perceived disparity in their two different lives. It’s important to remember that while not everyone may have the means or resources to help directly, empathy and understanding can go a long way toward fostering connections across socio-economic divides.
Avec ellmer - output structuré
https://ellmer.tidyverse.org/articles/structured-data.html
Conclusion
Enseignements
- Processus très itératif et empirique
- Approche “ligne par ligne” ou “tout d’un coup”
- Des résultats assez inégaux :
- Selon les modèles
- Selon les cas d’usage
- Selon le type de données
- Un respect des prompts approximatifs
- Intéressant en complément de méthodes plus classiques
ellmerest plus puissant mais moins simple d’usage
Assez similaires à https://posit.co/blog/llm-hackathon-lessons-learned/